 大模型学习笔记
大模型学习笔记
本文由 简悦 SimpRead (opens new window) 转码, 原文地址 blog.csdn.net (opens new window)
# 基础
# NLP 基础任务
- 词性标注:每一个词的词性(名词等)
- 实体识别:客观实体的识别,例如人名,时间等
- 共指消解:代词指代内容的识别
- 语法依赖关系:识别语法关系
# 词表示
one-hot vector:将词表达为一个 0-1 向量,向量的长度为词表的长度,,例如 [0,0,0,1,0,0...]
缺点: 每个词向量都是正交 (opens new window)的,无法计算词的相似性
上下文表示:词向量长度也是词表的长度,但是表示的是上下文其他词语出现的次数

缺点: 对空间存储需求大,且出现频率低的词,其词向量很稀疏
word embeding:利用深度学习将词投影到词向量,例如 word2vec
# 语言模型
两个基本能力:
- 判断一个词序列组成一个句子的概率
- 判断下一个词出现的概率
# N-gram
根据前面出现的 n-1 个词计算出现第 n 个词的概率

缺点:n 越大,对存储的要求越大,前文越长,统计结果很稀疏,且无法关注词的相关性
例如 the cat is walking 和 the dog is running,按照 n-gram 计算相似度为 0
上述方法最后的输出都是 softmax 之后,输出一个和词表长度一样的向量,缺点是计算资源和存储资源消耗过多,现有两种处理方法
# Hierarchical Softmax
根据词表建立哈夫曼树

则输出方式变为,经过 sigmoid(不需要进行所有量的指数运算了)后输出向量,向量的长度与哈夫曼树的节点相同,代表在每个节点选择左边或右边的概率
# 负采样
也就是在输出时,不对所有节点都进行 softmax,而是选取少量负样本进行 softmax,例如下面这个例子,从 too 预测 never,只需要选择少量负样本(非 never 的词),一起进行 softmax 即可

# sub-sampling
用来平衡常见词和罕见词,对于 “的” 等这样的常见词应该去除,下面这个公式表示当一个词语出现次数越多,其被去除的概率越大

# soft sliding window 动态滑动窗口
前面在进行 Word2vec 时,滑动窗口是固定的,这意味这其认为在窗口内的所有词地位都是一样的
但是其实距离 target 较近的 context 词应该更重要,所有设置动态滑动窗口
先设置一个最大的窗口大小值 s,然后在 1 到 s 中采样窗口进行训练,这样距离 target 较近的 context 词采样的次数会相比更多
# 自回归和自编码模型综述
https://zhuanlan.zhihu.com/p/483785458 (opens new window)
# Transformer

# BPE(Byte-Pair Encoding)
https://zhuanlan.zhihu.com/p/701869443 (opens new window)
原理:将词表先用空格分隔,然后构建基础词表,再根据词对的频率更新词表
例如:

拿到词表,先构建基础 vocabulary,然后去查找词对的频率(例如 "lo","es")等,然后发现频率最高的是 “es”,于是更新 vocabulary,加入 “es”,去掉 "e",得到新的词表
循环这个过程
优势
- 首先,直接按空格进行分词会导致词表大小不必要的庞大,如果希望限定词表大小还需要进一步考虑词表中 token 优先级的设定(即当容量填满时如何淘汰 token)
- 其次,按空格分词会导致分词粒度太大。这会导致大量的 out of vocabulary (OOV) 的问题,并且缺乏泛化性。下面我们具体解释下泛化性。
例如按空格分词的词表为 [rich, old, older, oldest, hard, harder, hardest] ,而如果使用子词 er,est ,词表变为 [rich, old, hard, er, est],即节省了空间,还能在一定程度上学到词之间的相关性,避免一部分 OOV 问题(例如现有方案对于 [richest](https://zhida.zhihu.com/search?content_id=244101608&content_type=Article&match_order=1&q=richest&zhida_source=entity "richest") 也可以进行合理的编码,而在原始的方案中会变成 unknown)。
所以,用 sub-word (opens new window) (子词)进行编码的好处呼之欲出。既能节省空间,又能提升泛化性来解决 OOV 问题
# PE(Positional Encoding)
不像 rnn 和 lstm 等可以天然记录词的位置信息,transfomer 必须在输入层就加入位置信息:

当 embeding 输出是一个 nd 的向量(n 为词数,d 为每个词 embeding 后的维度),那么 PE 结果也应该是 nd,然后总体的输入为 BPE+PE

优势:
- 对于每个词,及词的每个维度的位置编码都是不一样的
- 从下面的公式可以看出,这种编码方式更关注词的相对位置,而不关注绝对位置 i

# Word Embedding
参考:Transformer 之逐层介绍 - 知乎 (zhihu.com) (opens new window)
在 Transformer 模型中,词嵌入(Word Embedding)通常有两种来源:预训练模型和从头开始训练。
预训练模型:在这种方法中,词嵌入是通过使用如 Word2Vec、GloVe 或其他预训练词嵌入模型在大规模文本数据集上训练得到的。这些预训练的词向量能够捕捉词与词之间的语义关系,并将每个词表示为一个固定维度的向量。然后,这些预训练的词嵌入可以作为 Transformer 模型的初始输入。
从头开始训练:在这种方法中,Transformer 模型的词嵌入矩阵是随机初始化的,然后在训练过程中学习得到。这意味着模型将根据特定任务的数据从头开始学习词嵌入。这种方法不依赖于预训练模型,但可能需要更多的数据和计算资源来训练模型。
文本序列被映射成词汇表 (opens new window)的单词 ID 的数字序列。嵌入层再将每个数字序列射成一个嵌入向量,这是该词含义的一个更丰富的表示。

在经过 embedding 之后,在进入 attention 之前,矩阵会乘一个
原因:embedding matrix 的初始化方式是 xavier init,这种方式的方差是 1/embedding size,因此乘以 embedding size 的开方使得 embedding matrix 的方差是 1,在这个 scale 下可能更有利于 embedding matrix 的收敛。
Transformer 3. word embedding 输入为什么要乘以 embedding size 的开方 - 知乎 (zhihu.com) (opens new window)
# Scaled Dot-Product Attention
参考 Transformer 模型是什么?带你从零详细解读 Transformer 模型(图解最完整版)_狐说天下的技术博客_51CTO 博客 (opens new window)

举一个例子说明 QKV 是什么:
假设现在有一些商品的名字(K)和他们的价格(V),然后我自己有一个购买意向(比如我一定买一些苹果,可能买一下橘子等等,既为 Q),通过 Q 与 K 做运算得到一个商品的购买偏向,再与 V 运算得到我最终需要花费多少
计算公式:

# Encoder

# Batch Norm & Layer Norm
假设 m 个序列,每个序列长度为 n,每一个词编码维度为 d,编码后为(m,n,d)
batch norm 是针对每一个维度进行规范化(进行 m*d 次),但是由于序列的长度是变化的,这样的方法会不稳定
layer norm 是针对一个词的所有维度进行规范化,不需要考虑序列长度(进行 m*n 次)

# 训练优化方法
3-9 Transformer 结构 -- 优化 Tricks_transformer 中 dropout 放在哪里 - CSDN 博客 (opens new window)
• Checkpoint averaging(检查点平均)
在训练期间,Transformer 模型通常会保存多个检查点(即不同时间点的模型参数)。Checkpoint Averaging 技巧是将这些检查点的参数进行平均,生成一个平均模型。这可以提高模型的泛化能力和鲁棒性,并减少过拟合的风险。
• ADAM optimizer(自适应矩估计优化器)
ADAM(Adaptive Moment Estimation)优化器是一种常用的优化算法,用于调整模型的参数以最小化损失函数。它结合了 AdaGrad 和 RMSProp 的优点,通过自适应地计算每个参数的学习率和动量,能够在训练过程中更有效地更新模型参数。
• Dropout during training at every layer just before adding residual(Dropout 正则化)
Dropout 是一种正则化技术,用于减少模型的过拟合。在 Transformer 模型中,Dropout 被应用于每个层的输入,即在添加残差连接之前。这有助于随机地丢弃一部分神经元的输出,以减少它们之间的依赖关系,并增加模型的鲁棒性。
• Label smoothing(标签平滑)
标签平滑是一种用于改善模型训练和泛化能力的技巧。在 Transformer 模型中,当进行多类别分类任务时,传统的独热编码标签可能会导致过于自信的预测。通过标签平滑,将一部分概率质量从正确标签分配给其他标签,以减少模型的过拟合和提高泛化能力。
• Auto-regressive decoding with beam search and length penalties(自回归解码与束搜索和长度惩罚)
在生成目标序列时,Transformer 模型通常使用自回归解码策略。这意味着模型每次生成一个单词时,将其作为输入,并使用生成的单词继续生成下一个单词,以此类推。为了得到更准确的生成结果,一种常用的策略是使用束搜索(beam search)来探索多个可能的生成序列,并根据得分进行选择。此外,为了避免生成过长的序列,可以使用长度惩罚来鼓励更短的输出序列。
# 并行计算
Transformer 之十万个为什么?_teacher force-CSDN 博客 (opens new window)
transfomer 的并行计算主要体现在训练阶段的 encoder 和 decoder 和预测阶段的 encoder 部分
encoder 阶段
decoder 阶段
①、teacher force
对于 teacher force,是指在每一轮预测时,不使用上一轮预测的输出,而强制使用正确的单词,过这样的方法可以有效的避免因中间预测错误而对后续序列的预测,从而加快训练速度,而 Transformer 采用这个方法,为并行化训练提供了可能,因为每个时刻的输入不再依赖上一时刻的输出,而是依赖正确的样本,而正确的样本在训练集中已经全量提供了。值得注意的一点是:Decoder 的并行化仅在训练阶段,在测试阶段,因为我们没有正确的目标语句,t 时刻的输入必然依赖 t-1 时刻的输出,这时跟之前的 seq2seq 就没什么区别了。
②、masked self attention
我们在 5 里说到,多头注意力意味着多组 KQV 进行 self-attention 运算,不同于 LSTM 中的一步步的按部就班的运算,而是 KQV 的运算可以是同时计算的(这是因为每 QKV 的线性变换不同,计算互不影响)
注意 transformer 的运算复杂度,乘法运算不一定比 LSTM 少,但因为可以进行同步运算,因而可以依靠硬件加速。
multi-head attention 是每一个 head 都进行了 KQV 生成以及 attention 的计算,这些计算是同步实现的,也就是并行实现的,因而可以同时获取不同空间的特征。
# Q&A
计算机视觉面试题 - Transformer 相关问题总结 - 知乎 (zhihu.com) (opens new window)
Transformer 面试常见问题总结 - CSDN 博客 (opens new window)
Transformer 为何使用多头注意力机制?
提高模型的理解和表达能力,不同的头关注的是不同层次的信息,例如对于一篇文稿,有的头关注的是字体,有的头关注的是颜色,有的头关注的是语法等,当然 Transformer 是一个不可解释的模型,这一切都是我们的假设
Transformer 为什么 Q 和 K 使用不同的权重矩阵生成,为何不能使用同一个值进行自身的点乘?
因为 Q 和 K 代表的信息不同,Q 表示的是查询信息,K 代表的是键信息,使用不同的权重能使其更好的发挥自己的作用,增强表达能力和泛化能力,如果使用同一个,会发现结果是一个对称矩阵,投影到了一个空间,泛化性能很差
在计算 attention 时,为什么进行 softmax 之前需进行 scaled(为什么除以 dk 的平方根)
在计算 self-attention 时,需要进行 softmax 操作,以计算每个输入序列位置对其他位置的注意力权重。为了避免 softmax 函数的指数计算导致数值溢出或下溢,Transformer 模型中使用了 scaled dot-product attention,即在 softmax 之前对向量点乘结果进行了缩放操作,用于控制点乘结果的大小。
具体来说,该缩放操作是将点乘结果除以一个值,这个值是输入向量的维度的平方根,即 dk 的平方根,其中 dk 表示每个向量的维度。这个缩放因子的作用是:当输入向量的维度增加时,点乘结果的大小也会增加,导致 softmax 函数的指数计算变得困难,缩放因子能够使点乘结果的大小保持在一个合适的范围内,从而提高计算的稳定性。Transformer 面试常见问题总结 - CSDN 博客 (opens new window)
简单介绍一下 Transformer 的位置编码?有什么意义和优缺点?
计算机视觉面试题 - Transformer 相关问题总结 - 知乎 (zhihu.com) (opens new window)
其他位置编码方法?
六种位置编码的代码实现及性能实验 - 知乎 (zhihu.com) (opens new window)
大语言模型中常用的旋转位置编码 RoPE 详解:为什么它比绝对或相对位置编码更好?- 腾讯云开发者社区 - 腾讯云 (tencent.com) (opens new window)
# ELMo
参考
00 预训练语言模型的前世今生(全文 24854 个词) - B 站 - 水论文的程序猿 - 博客园 (opens new window)
一个专门做词向量的模型,解决问题:word2vec 无法解决一词多义的问题

- E1: 是对单词的简单编码,类似与 word2vec,使用的是 cnn 编码,也无法区分一词多义
- E2,E3:本质上采用双向 LSTM,理解每一个单词的前文和后文的信息,并根据前后文给出当前单词的 embedding
ELMo 采用了典型的两阶段过程:
- 第一个阶段是利用语言模型进行预训练;
- 第二个阶段是在做下游任务时,从预训练网络中提取对应单词的网络各层的 Word Embedding 作为新特征补充到下游任务中。也就是说会综合 E1、E2、E3 当成最后的 embeding 结果作为子任务的输入

# Feature-based 和 Fine-tune
参考
#深入理解# NLP 中的 Feature-based 和 Fine-tune 两种学习方法_feature based finetune-CSDN 博客 (opens new window)
基于神经网络的语言模型根据学习方法不同大体可以分为两大类,分别是 Feature-based 和 Fine-tune
- Feature-based 方法是通过训练神经网络从而得到词语的 embedding,换句话说就是通过神经网络得到更恰当的向量来表示词库中的每一个词语,Feature-based 方法不使用模型本身,而是使用模型训练得到的参数作为词语的 embedding;feature-base 方法最典型的例子就是 ELMO 和 word2vec
- Fine-tune 方法会根据下游特定的任务,在原来的模型上面进行一些修改,使得最后输出是当前任务需要的。这些修改一般是在模型的最后一层,或者在现有的网络后添加一个网络结构用于匹配下游的各种任务;GPT1 GPT2 就采用了 Fine-tune 方法,GPT3 得益于海量的与训练样本和庞大的网络参数,不在需要 fine-tune 过程;BERT 论文采用了 LM + fine-tuning 的方法,同时也讨论了 BERT + task-specific model 的方法。
# NLP 四范式
目前学术界一般将 NLP 任务的发展分为四个阶段即 NLP 四范式:
- 第一范式:基于传统机器学习模型的范式,如 tf-idf 特征 + 朴素贝叶斯等机器算法;
- 第二范式:基于深度学习模型的范式,如 word2vec 特征 + LSTM 等深度学习算法,相比于第一范式,模型准确有所提高,特征工程的工作也有所减少;
- 第三范式:基于预训练模型 + fine tuning 的范式,如 BERT + finetuning 的 NLP 任务,相比于第二范式,模型准确度显著提高,但是模型也随之变得更大,但小数据集就可训练出好模型;
- 第四范式:基于预训练模型 + Prompt + 预测的范式,如 BERT + Prompt 的范式相比于第三范式,模型训练所需的训练数据显著减少。
# Prompt learning
参考
【NLP】Prompt Learning 超强入门教程 (opens new window)
目的:提升预训练模型的泛化性
例如一般预训练模型都是使用【mask】去进行完形填空,而下游任务有很多,例如情感分类,如果能讲下游任务的任务形式转换未和预训练模型一样的模式,就可以省去微调的过程
Prompt 的工作流包含以下 4 部分:
- Prompt 模版(Template)的构造
- Prompt 答案空间映射(Verbalizer:fantastic=postive,boring=negtive)的构造
- 文本代入 template,并且使用预训练语言模型进行预测
- 将预测的结果映射回 label。

# Template 构造方法
根据任务类别人为构造
# 
https://zhuanlan.zhihu.com/p/375934846 (opens new window)
# delta-tuning
在预训练模型微调中的 delta-tuning 一般是指固定 PLM 的参数,额外增加一部分参数用来针对不同的下游任务来微调,从而避免全参数微调,节省资源并且可以在不同的子任务上使用大模型 (opens new window)学到的通用知识。
(8 封私信 / 80 条消息) 什么是 delta-learning?or ∆-Learning? - 知乎 (zhihu.com) (opens new window)
# 增量式
通俗解读大模型主流微调方法:从 Prefix Tuning、P-Tuning V1/V2 到 LoRA、QLoRA - 知乎 (zhihu.com) (opens new window)
# adapter-tuning
在 transfomer layer 中的 feed-forward 层下层加入两层全连接层,在微调时只训练这部分参数

adapter 的一种优化方案,将加入的全连接层移动到外面,通过先降维再升维的方式做到精度一致,最大的优势在于反向传播时不需要经过原始的 transfomer layer,计算更简单

# Prefix Tuning
Prefix Tuning 是一种针对大型预训练语言模型(如 GPT-2、GPT-3)的微调方法,它在不改变底层模型参数的情况下,通过修改输入的前缀来优化模型的效果。这种方法在自然语言生成任务(NLP)中尤其有效,并且在数据较少的场景下也能表现出色。
原理: Prefix Tuning 的核心思想是在模型的输入序列前添加一系列可训练的连续向量,称为前缀(prefix)。这些前缀作为额外的输入与原始输入一起被模型处理。**在训练过程中,只有前缀向量的参数是可训练的,而模型的主要参数被冻结。**通过优化这些前缀的参数,模型可以学会生成适应新任务输出的提示,而无需改变模型的主要参数。

对于自回归模型,只需要在输入数据前加入前缀,对于 encoder-decoder 模型,两侧都要加入 prefix
为了形象说明,举个例子,对于 table-to-text 任务,context 是序列化的表格,输出是表格的文本描述,使用 GPT-2 进行生成;对于文本摘要,是原文,是摘要,使用 BART 进行生成 对于自回归 (opens new window) (Autoregressive) 模型,在句子前面添加前缀,得到
这是因为合适的上文能够在 fixed LM 的情况下去引导生成下文(比如 GPT3 的 in-context (opens new window) learning),对 Encoder-Decoder 模型来说,Encoder 和 Decoder 都增加了前缀,得到
这是因为 Encoder 端增加前缀是为了引导输入部分的编码 (guiding what to extract from),Decoder 端增加前缀是为了引导后续 token 的生成 (influence the generation of by steering the next token distribution)
该方法其实和构造 Prompt 类似,只是 Prompt 是人为构造的 “显式” 的提示,并且无法更新参数,而 Prefix 则是可以学习的 “隐式” 的提示。
同时,为了防止直接更新 Prefix 的参数导致训练不稳定的情况,特在 Prefix 层前面加了 MLP 结构 (相当于将 Prefix 分解为更小维度的 Input 与 MLP 的组合后输出的结果),训练完成后,只保留 Prefix 的参数。
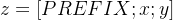
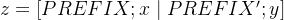
缺点:
较难训练,且模型的效果并不严格随 prefix 参数量的增加而上升,这点在原始论文中也有指出
会使得输入层有效信息长度减少。为了节省计算量和显存,我们一般会固定输入数据长度。增加了 prefix 之后,留给原始文字数据的空间就少了,因此可能会降低原始文字中 prompt 的表达能力
# 指定式
直接指定在微调过程中能改变的参数
# BitFit
大模型参数高效微调技术原理综述(二)-BitFit、Prefix Tuning、Prompt Tuning - 知乎 (zhihu.com) (opens new window)
BitFit 是一种稀疏微调方法,其中仅修改模型(或其子集)的 bias 项。

# 重参数化
中心思想是,将参数转换为低秩模式,以微调更少的参数。
# LoRA
LORA 微调系列 (一):LORA 和它的基本原理 - 知乎 (zhihu.com) (opens new window)
LoRA 通过仅训练低秩矩阵,然后将这些参数注入到原始模型中,从而实现对模型的微调
也就是说,预训练之后的 W~=W+△W,可以使用两个小矩阵来近似得到△W

# 
# 训练优化
# KV Cache
参考:
https://juejin.cn/post/7362789570217885759 (opens new window)
在 Transformer 的解码器中,其是带 Masked 的 Self Attention,造成的结果为任意时刻的 attention 只与当前时刻的 Q 有关,且 V 也只与同一时刻的 Q 有关
在原始的方案中,对于每一时刻的 attention,都需要重新计算之前所有时刻的 KV,但是其实之前时刻的 KV 是不会变化的,所有可以将之前的 KV 都缓存起来

# 数据并行
数据并行(Data Parallelism)是一种在大规模数据处理和训练大型神经网络中常用的并行计算技术。其核心思想是将大型数据集分割成多个小块,并将这些数据块分配给多个处理器(例如 GPU)同时处理。每个处理器运行相同的程序,但处理的数据子集不同。

例如最基础的思想,现将参数进行广播复制到每一个显卡,将数据分成多份分发到不同显卡,然后每个显卡负责一块数据的梯度计算,最后将梯度结果规约到一个服务器,最后完成参数更新和优化。
缺点:
通信开销:在数据并行中,不同处理单元之间需要频繁通信以同步数据和结果,这可能导致通信开销随着处理单元数量的增加而显著增加,从而影响整体性能。
内存占用:由于每个处理单元都需要存储模型的完整副本,因此数据并行可能导致内存占用显著增加,尤其是在处理大规模数据集时。
负载均衡问题:如果数据切分不均匀,某些处理单元可能会过载,而其他处理单元则可能处于空闲状态,这会影响整体的训练效率。
分布式数据并行
之前的方案是存在一个专门的参数服务器,管理所有参数,且负责参数的更新和广播,分布式数据并行取消了这个参数服务器,使得每个显卡都得完整的梯度信息进行更新

显卡的合作模式
1、broadcast

2、reduce

3、all reduce

4、reduce scatter
out0 等于 in0 的前四分之一加上 in1 的前四分之一...

5、all gather

# 模型并行
在做矩阵乘法时,可以将其拆分为多个部分结果相加的形式,那在深度学习中,也可以将模型参数分成多分,然后结果聚合的形式以达到模型并行,前提是输入 x 一致,也就是说无法使用数据并行

将模型参数分成 n 分,然后针对相同的输入数据做矩阵乘法,最后将结果 all gather 起来

# ZeRO
ZeRO(Zero Redundancy Optimizer)是一种先进的内存优化技术,旨在优化大规模深度学习模型训练过程中的内存使用。ZeRO 通过减少冗余内存占用,使得在有限的硬件资源上训练更大的模型成为可能。它主要通过以下三种级别的优化来实现这一目标:
stage1:每张显卡使用 reduce sactter 存储一部分梯度结果,然后使用对应的优化器进行优化,然后 update with all gather 后更新每个显卡的全部参数,保证参数一致

**stage2:*在第一阶段中,中间的 gradient 需要在反向传播结束之后才删除,在第二阶段,gradient 是动态删除的,例如在第 n 层的反向传播完成后,计算得到 gradient,就把第 n 层的 gradient 删除,以此类推,而不需要等到所有反向传播做完
stage3:每张显卡只保存一部分的模型参数,但是在反向传播计算的过程中还是需要先 gather 得到所有参数再计算,计算完就丢弃,不需要保存,相当于是时间换空间的做法。

# 流水线并行
模型并行主要针对的是线性层,将线性层矩阵分解为多个小矩阵分发到不同的显卡进行运算
流水线并行主要针对的是不同的网络层,例如一个三层的 transfomer,将三层参数分发到不同的显卡进行计算,但是第二层模型计算时需要第一层的结果,所以其弊端就是,一个时间内只有一层模型对应的显卡运行,会有资源浪费

# 其他细节
# 混合精度训练
深度学习中的数据类型介绍:FP32, FP16, TF32, BF16, Int16, Int8 ...-CSDN 博客 (opens new window)
FP16 和 FP32 (float) 的存储示例图


FP16 带来的问题

在模型训练中一般采用 FP32 进行训练,混合精度训练的意思是设置部分训练参数为 FP16 类型,以加速训练速度、减小内存消耗
一般来说 weight update = gradient*lr,学习率一般是 10^-5 数量级,那么 weight update 肯定不能用 FP16 存储
权重备份
https://zhuanlan.zhihu.com/p/570942198 (opens new window)

本质上这里的参数更新公式为:

只是在计算中 weight 采用 fp32 计算,然后再转为 FP16,这里我的理解是会将 weight 缩放以适应 fp16 的要求
# offloading
Offload 技术(也可以理解为混合部署或混合推理)将对象卸载到外部资源或将其分布在多种设备上以减少主设备的内存负载,常用用于在 GPU 显存有限的设备上优化内存使用。比如:将 GPU 显存中的权重卸载到 CPU 内存、NVMe/Disk。

由于 ZeRO 模式的运用,且一个 GPU 可对应多个 CPU,CPU 的计算速度不会成为模型推理的瓶颈。

# overlaping
overlapping 策略是指在模型训练过程中同时执行计算和数据传输的技术。这种策略旨在最大程度地减少计算资源的浪费,提高训练效率。
原始方案中,需要先 gather 第一层参数,然后计算第一层,然后 gather 第二层参数,然后计算第二层...
更新方案为,计算第一层参数时,同时 gather 第二层参数,以实现异步

通过实现 overlapping 策略,可以有效减少模型训练过程中的计算资源浪费,提高训练效率和整体性能。这种策略在训练大型模型时尤为重要,可以显著加快训练速度并提高训练效率
# checkpointing
一种对某些中间结果进行保存,以减少其他内存开销的方法,是一种以时间换空间的方式
以 transformer 举例
- without checkpointing:保存每一层的线性层中间结果(BP graph),在反向传播时才能进行线性层参数更新
- with checkpointing:只保留每一层大的 layer 的输入层,在反向传播时再临时计算 BP graph
如果一个模型有 24 层 transformer,每一层有 5 个线性层,那么保存的数据从 24*5 缩小到 24

# 模型压缩
# 知识蒸馏(knowledge distillation)
一分钟带你认识深度学习中的知识蒸馏 - 知乎 (zhihu.com) (opens new window)
知识蒸馏是一种模型轻量化的方法,通过先训练一个模型更大,参数更多,理解能力更强的 Teacher 模型,如何使用这个 Teacher 模型去训练一个小模型 Student 模型,已达到模型轻量化的目的。来自 Teacher 模型输出的监督信息称之为 knowledge(知识),而 student 学习迁移来自 teacher 的监督信息的过程称之为 Distillation(蒸馏)。
知识蒸馏的功能
1、提升模型精度
用户如果对目前的网络模型 A 的精度不是很满意,那么可以先训练一个更高精度的 teacher 模型 B(通常参数量更多,时延更大),然后用这个训练好的 teacher 模型 B 对 student 模型 A 进行知识蒸馏,得到一个更高精度的模型。
2、降低模型时延,压缩网络参数
用户如果对目前的网络模型 A 的时延不满意,可以先找到一个时延更低,参数量更小的模型 B,通常来讲,这种模型精度也会比较低,然后通过训练一个更高精度的 teacher 模型 C 来对这个参数量小的模型 B 进行知识蒸馏,使得该模型 B 的精度接近最原始的模型 A,从而达到降低时延的目的。
3、图片标签之间的域迁移
用户使用狗和猫的数据集训练了一个 teacher 模型 A,使用香蕉和苹果训练了一个 teacher 模型 B,那么就可以用这两个模型同时蒸馏出一个可以识别狗,猫,香蕉以及苹果的模型,将两个不同与的数据集进行集成和迁移
知识蒸馏的一般原理:

对于原始数据,student 模型可能无法学习到其内部关系,例如对于一个分类任务,label 往往是单一的 0-1 分布,学生模型可能难以高精度拟合
这时可以训练一个更大的模型,让其去学习这个 0-1 分布,然后其输入可以经过 softmax 等方式,得到软 label,即分类的概率分布,这样的输出包含信息更多,即熵值更大,再使用这个概率分布 label 去训练 student 模型。
整个过程类似老师先去学习一个晦涩难懂的知识,然后再以通俗的方式教给学生
针对最基础的知识蒸馏方式,有许多变式方法:
- 从 teacher 模型中间层学习
- 从 teacher 模型 embeding 层和输出层学习
- 针对 transfomer 模式,从 teacher 模型中间的 attention matrics 中学习
# 模型剪枝
# 模型量化
LLM 基础|模型量化到底是啥?看这一篇就够了! - 知乎 (zhihu.com) (opens new window)
在模型中,将数值的位数减小为定值,已达到降低显存,提升速度的目的,简单直白点讲,即原来表示一个权重需要使用 float32/float16 表示,量化后只需要使用 int8 来表示就可以啦,仅仅这一个操作,我们就可以获得接近 4 倍的网络加速。
- 线性量化
- 普通线性量化
- 对称量化
- 非对称量化
- 非线性量化
- 逐层量化、逐组量化和逐通道量化
- 权重量化、权重激活量化
- 在线量化和离线量化
应用:
BinaryBERT

BinaryBERT 是一种对 BERT 模型进行极限量化的方法,它通过权重二值化(weight binarization),即将模型中的权重参数转化为 1 比特的值,从而极大地减少模型大小和计算量。这种方法可以将模型大小减少 32 倍,并用加法代替大多数浮点数乘法,从而降低能源消耗和芯片上的面积使用。
原理: BinaryBERT 的关键在于如何有效地训练一个二值化的 BERT 模型。直接训练一个二值化的网络是困难的,因为二值化的权重会导致模型的损失景观变得非常复杂和不规则。为了解决这个问题,BinaryBERT 采用了一种称为 “三值权重分裂”(ternary weight splitting)的方法。这种方法首先训练一个半尺寸的三值 BERT 模型,然后将这个三值模型的权重等价地分裂成二值权重和潜全精度权重,作为全尺寸 BinaryBERT 的初始化。这样,BinaryBERT 就继承了三值模型的良好性能,并且可以通过在新架构上进一步微调来提高性能。
训练过程:
- 首先训练一个三值 BERT 模型。
- 应用三值权重分裂操作,将三值模型的量化权重和潜全精度权重等价地转换,初始化全尺寸的 BinaryBERT。
- 在新架构上对 BinaryBERT 进行微调,以进一步优化性能

模型量化和混合精度训练都是讲参数的精度降低以提升训练速度,但是其针对的对象不一样,以 transformer 为例:

# 参数共享
参数共享的基本思想是在整个模型的不同部分使用相同的参数,而不是为每个任务或模型组件训练唯一的参数集。
嵌入层共享:词嵌入矩阵在整个模型中共享,这意味着每个单词的向量表示在整个模型中是一致的。
层归一化参数共享:在 Transformer 架构中,层归一化(Layer Normalization)的尺度(scale)和偏移(shift)参数通常在每个注意力机制和前馈网络层中共享。
注意力机制中的参数共享:在多头注意力(Multi-Head Attention)中,每个头的缩放因子(scaling factor)可以共享。
前馈网络参数共享:在前馈网络(Feed-Forward Network)中,线性变换的权重可以在不同的层中共享。
跨任务共享:在多任务学习中,模型的一部分可以在不同的任务之间共享,以利用任务之间的共同特征。
跨层共享:在某些模型架构中,如 LeBERT(Layer-wise Efficient BERT),不同 Transformer 层的权重可以共享,以提高效率。
跨模态共享:在处理不同类型数据(如文本、图像和声音)的模型中,可以在处理不同模态的共享层中使用相同的参数
应用:ALBERT
ALBERT 通过两种主要的技术来减少参数数量:分解嵌入参数化和跨层参数共享。
分解嵌入参数化:ALBERT 将词嵌入矩阵分解成两个较小的矩阵,从而减少了模型的参数量。具体来说,它首先将 one-hot 编码 (opens new window)的词向量映射到一个较低维度的嵌入空间,然后再映射到隐藏空间,这样做有效地将嵌入参数从 O(V×H) 减少到 O(V×E + E×H),其中 V 是词汇表大小,H 是隐藏层大小,E 是嵌入空间的维度。
跨层参数共享:在 ALBERT 中,所有层的参数都是共享的。这意味着不同层的 Transformer 网络使用相同的权重,从而进一步减少了模型的参数量。这种设计决策在实验中被证明是有效的,并且与 BERT 相比,ALBERT 在层与层之间的转换更加平滑,这表明权重共享有助于稳定网络参数。
相比于 bert,其对 NSP 任务进行了改进,因为 bert 的 NSP 任务正例就是用的一个文档里面连续的两句话,但是负例使用的是不同文档里面的两句话。这就导致任务包含了主题预测,而主题预测又要比两句话连续性的预测简单太多。新的方法使用了 sentence-order prediction(SOP), 正例的构建和 NSP 是一样的,不过负例则是将两句话反过来。
# 低秩分解
模型压缩之模型分解篇:SVD 分解,CP 分解和 Tucker 分解 - 知乎 (zhihu.com) (opens new window)
低秩分解是一种在大模型压缩中常用的技术,它通过将模型中的大矩阵分解为两个或多个小矩阵的乘积来减少模型的参数数量和计算复杂度。这样做不仅可以减少模型的存储需求,还可以加快模型的运算速度。

# 大模型 QA
目前主流的开源 LLM(语言模型)模型体系
- GPT:自回归模型,采用 transfomer 的 decoder 部分
- bert:自编码模型,采用 transfomer 的 encoder 部分
- RoBERTa:对 bert 的改进,数据更多,更大的 batch size 等,还有一些改进,例如不在使用 NSP(Next Sentence Prediction) 任务,将静态 mask 换成动态 mask
- RoBERTa 中引入了动态 mask 的策略,原论文中将原始数据复制 n 份,每份都进行随机的静态 mask,从而每份数据的 mask 结果都不太一样。huggingface 中 data allcator 使用的是动态 mask,但不是复制数据,而是每一个 epoch 的 mask 策略都不同,这样就可以达到动态 mask 的效果了,从而使得每一个 epoch 的 mask 的情况都不同,更方便更胜内存。
- T5:encoder-decoder 模型
- XLNet
DeepSpeed
一文读懂 deepSpeed:深度学习训练的并行化 - CSDN 博客 (opens new window)
微软开发的一个深度学习优化库,主要优化策略包括三个方面
高效的并行化策略:DeepSpeed 支持多种并行化方法,包括数据并行、模型并行和流水线并行。这些方法可以灵活组合,以适应不同规模和复杂度的深度学习模型。通过并行化,DeepSpeed 能够显著提高训练速度和可扩展性。
内存优化技术:为了降低内存占用和提高训练效率,DeepSpeed 引入了 ZeRO(Zero Redundancy Optimizer)技术。ZeRO 通过将优化器的状态、梯度和参数在分布式环境中进行分割,从而减少了冗余的内存占用。这使得在有限的内存资源下训练更大的模型成为可能。
混合精度训练支持:DeepSpeed 支持混合精度训练,即同时使用单精度和半精度浮点数进行训练。这种方法可以在保持模型性能 (opens new window)的同时,减少内存占用和计算时间,降低能耗。